Một vài kinh nghiệm của tôi khi sử dụng AWS Lambda
Mở đầu#
Một trong những xu hướng mà tôi được tiếp cận khi sang làm DevOps ở một division trong Caterpillar chính là công nghệ Serverless. Project đầu tiên mà tôi nhận được chính là migrate hệ thống từ sử dụng server vật lý cổ điển lên sử dụng AWS Lambda. Đây là một trải nghiệm vô cùng thú vị khi tôi có cơ hội rất tốt để có thêm một mindset mới để thiết kế một hệ thống dựa hoàn toàn vào một nhà cung cấp hạ tầng và không phải lo lắng về những lỗi về server cổ điển như trước. Tất nhiên, không có bữa trưa nào là miễn phí, việc chuyển giao không chỉ đơn giản là port các method trong code cũ thành các function và cứ thế mà nó chạy, tôi đã tốn khá nhiều thời gian để re-engineer lại hệ thống để đảm bảo chi phí tiết kiệm và tốc độ được cải thiện. Dưới đây là một vài kinh nghiệm tôi thu thập được trong quá trình chuyển giao.
Thiết kế một API thuần sử dụng các dịch vụ của AWS#
Một API có rất nhiều thứ chuyển động, trong đó sẽ sẽ có các thành phần sau:
- Lưu trữ
- File tĩnh: Lưu trữ các file gần như không bao giờ thay đổi, (có thể) thường xuyên được lấy ra bởi người dùng nhưng gần như không bao giờ được lấy ra và xử lý tiếp API
- File động: Bao gồm các file thường xuyên được truy xuất bởi API dùng cho các mục đích tính toán hoặc thay đổi
- CSDL
- SQL: Lưu các dữ liệu có tính cấu trúc cao, quan hệ với nhau rất lằng nhằng, đảm bảo tính ACID, lưu lượng truy vấn tương đối nhiều và rất phức tạp
- NoSQL: Lưu trữ các dữ liệu phi cấu trúc, lưu lượng truy vấn trung bình đến cao, truy vấn có thể đơn giản hoặc phức tạp tuỳ vào mục đích sử dụng, yêu cầu tốc độ truy vấn phải rất nhanh
- Cache: Chứa các dữ liệu có thời gian sống ngắn, dùng để chứa các dữ liệu thường xuyên được truy vấn trong một thời gian ngắn
- Bảo mật
- Mật khẩu các tài nguyên như mật khẩu DB
- Các key giải mã dữ liệu
Thông qua các thành phần trên, tôi có thể liệt kê sơ qua các tài nguyên sẽ sử dụng trong AWS
- File tĩnh: S3, một lựa chọn khá hiển nhiên và đơn giản. Tuỳ thuộc vào mục đích và tần suất truy xuất dữ liệu, ta có thể lưu trữ chúng trong các bucket với tiering khác nhau
- File động: EFS, AWS hỗ trợ việc mount EFS vào Lambda, qua đó ta có thể dễ dàng thao tác với dữ liệu giống như ta đang thao tác với file trong ổ cứng của các server cổ điển
- SQL: Aurora RDS Serverless với giá thành rẻ và khả năng scale tốt hơn
- NoSQL: DynamoDB với key được sinh ra dựa trên các rule có sẵn dữa vào dữ liệu của SQL hoặc key từ dữ liệu từ người dùng gửi lên
- Cache: ElastiCache Redis nhờ giá thành rẻ, khá quen thuộc khi sử dụng
- Bảo mật: Secret Manager do AWS không hỗ trợ Vault của HashiCorp
Để minh hoạ (bao gồm cả thiết kế mạng), tôi có hình sau:
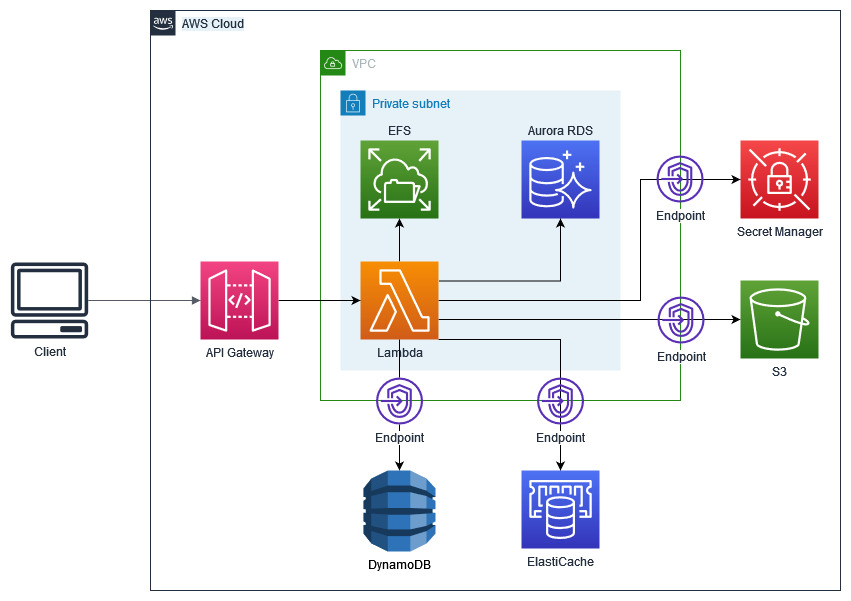
Topology hệ thống Aperture
Về cơ bản, thiết kế như trên (không bao gồm các tài nguyên nằm ngoài AWS) đảm bảo gần như đầy đủ các yêu cầu của một API server với chi phí tương đối rẻ, do AWS Lambda và API Gateway không tính tiền Upfront nếu không có request tới, tức là dùng tới đâu trả tiền tới đó (tất nhiên trừ khi bạn dùng Provisioned Concurrency).
Tận dụng tối đa tài nguyên trong vòng đời sống của Lambda Runtime#
Dưới đây là biểu đồ trạng thái sơ lược flow chạy Lambda khi được invoke (ví dụ như API Gateway invoke lambda):
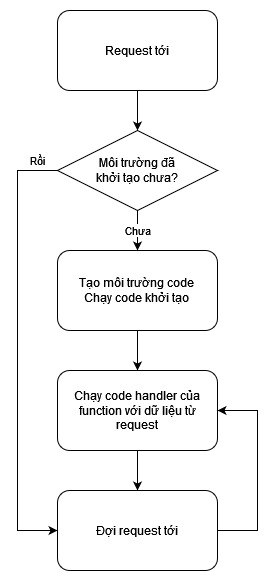
Lambda Execution Flow Aperture
Với những ai chưa biết, thay vì tạo mới một runtime cho mỗi lần request, AWS sẽ tạo ra một môi trường chạy code cô lập (hãy tưởng tượng nó như một cái docker container) và giữ nó sống (hoặc gọi là warm). Môi trường này sẽ tiếp tục warm một lúc và tự tắt nó đi khi không có request tới nó nữa sau một khoảng thời gian đợi (ta không quyết định được khoảng thời gian đợi này). Sau khi khởi tạo, các biến global (cả trong code lẫn trong layer) sẽ vẫn được lưu ở đó chứ không bị giải phóng như các biến nằm trong các function.
Để hiểu rõ hơn, ta sẽ sử dụng một ví dụ Python dưới đây:
# file name: lambda_function
import pymysql
conn = pymysql.connect(host="somehost", user="root", passwd="password", db="db_name", connect_timeout=5)
# lambda will call this function on every requests
def lambda_handler(event, context):
get_all_usernames()
return {
"statusCode": 200,
"message": "success",
"body": {}
}
def get_all_usernames():
with conn.cursor() as cur:
cur.execute("SELECT id, username FROM user")
result = cur.fetchall()
return dict(result)
Như ở ví dụ trên, việc Tạo môi trường code chính là import các thư viện và chạy code không nằm trong các function, như việc tạo connection conn tới MySQL. Cũng ví dụ trên, sau khi chạy xong một request, biến conn sẽ không bị giải phóng nên các request về sau được chạy ở trong function đã tạo này không phải tạo lại conn nữa. Ưu điểm của phương pháp này là tiết kiệm được thời gian khởi tạo các tài nguyên khởi tạo lâu (việc khởi tạo một connection mới vào RDS có thể tốn từ 30ms đến 100ms), nhờ vậy làm giảm thời gian chạy của lambda, khiến API response nhanh hơn và trên hết là giảm chi phí vận hành.
Ngoài ra, ngoài các biến dữ liệu trong code được giữ lại (như trong ví dụ trên), giữa các lần chạy, Lambda còn giữ lại dữ liệu trong thư mục /tmp với kích thước tối đa là 512M. Vậy nên thông qua việc lưu trữ dữ liệu lâu dài trong các global variable, chúng ta hoàn toàn có thể lưu dữ liệu vào trong thư mục này như một dạng cache để đẩy nhanh quá trình xử lý. Tất nhiên, việc lựa chọn cách sử dụng nằm ở bạn, đây chỉ là một vài ví dụ về cách tận dụng vòng đời của Lambda, hãy tìm thật nhiều cách để tìm ra các phương pháp sử dụng tối ưu tài nguyên.
Tinh chỉnh lượng tài nguyên cấp cho Lambda Runtime#
Một hệ thống API tốt cần phải đảm bảo cân bằng giữa hiệu năng và chi phí bỏ ra, một API lệch sang một trong hai cán cân trên đều gây ra thiệt hại về tiền bạc. Nếu API quá chậm sẽ phá hoại trải nghiệm của người dùng và làm giảm tín nhiệm của người dùng với sản phẩm. Nếu bỏ quá nhiều tiền để scale-up hệ thống API, theo Luật Amdahl thì chắc chắn số tiền bạn bỏ ra sẽ là hoang phí. Để hiểu rõ cần phải tinh chỉnh Lambda như thế nào cho hiệu quả, dưới đây là một vài đặc tính về sức mạnh tính toán và chi phí của Lambda:
Chi phí#
Công thức tính chi phí vận hành của Lambda có thể tính sơ qua như sau (Áp dụng với vùng us-east-1)
Chi phí vận hành của Lambda ($) = Thời gian chạy function (ms) * Dung lượng RAM (M) * $0.0000000021
(Công thức trên tính dung lượng RAM với bội của 128M)
Năng lực tính toán#
CPU time được cấp cho một Lambda function tỉ lệ thuận với số lượng RAM cấp cho function đó. Một cách hiển nhiên rằng, thời gian vận hành sẽ giảm nếu được cấp nhiều CPU time hơn. Nói cách khác, thời gian chạy tỉ lệ nghịch với lượng RAM. RAM càng nhiều thì code chạy càng nhanh. Đồng thời việc truy cập filesystem, xử lý mạng cũng sẽ nhanh hơn.
Vậy tối ưu thế nào?#
Đến đây, chúng ta phải chú ý để chọn CPU time hợp lý để đảm bảo thời gian chạy phải thấp, nhưng cũng không quá đắt. Rất tiếc, không có một viên đạn bạc nào có thể đưa ra một công thức tính thần kì giúp bạn đưa ra một số lượng RAM cần thiết trong mọi trường hợp. Cách làm đơn giản nhất để tối ưu chi phí là thử đi thử lại để chọn lấy một mức RAM hợp lý. Trong blog post của Lambda có để cập đến một phương pháp để bạn có thể chọn một mức RAM hợp lý để chạy function Lambda, đường dẫn ở đây.
Nói ra thì có vẻ dài dòng, nhưng sau khoảng thời gian dài tôi làm việc thì trên 90% các function cũng chỉ chia ra làm 2 loại:
- Thực hiện các công việc rất đơn giản và yêu cầu phải trả ra kết quả nhanh.
- Thực hiện các công việc phức tạp, tốn nhiều thời gian và năng lực tính toán.
Như bài toán của tôi thì trong một hệ thống lớn chỉ có 2 loại function:
- Endpoint function: Function serve trực tiếp API response ra cho người dùng. Chủ yếu connect vào database, cache và file tĩnh. Code của các function này tương đối ngắn và các tác vụ rất đơn giản.
- Background-job function: Function dùng để chạy các task tính toán hiệu năng cao, người dùng không được tương tác trực tiếp với các function này. Chủ yếu các function này sẽ sinh ra kết quả mà Endpoint function sẽ chọc vào để lấy.
Sau khi nhóm được các loại function vào với nhau rồi, thì ta chỉ cần phải thử trên vài function đại diện cho mỗi nhóm, và thử với 10% function không nằm vào 2 nhóm trên. Theo như kinh nghiệm của tôi sử dụng Lambda, thì có vài kết luận như sau:
- Tốc độ thực hiện function không tăng tuyến tính do luật Ahmdal, vì thế tăng RAM lên kịch khung chỉ phí tiền.
- Vì Lambda charge cả tiền cold-start, nên các function nào dùng nhiều mà cold-start cao (như các function dùng đến Pandas, SciPy và NumPy) sẽ bị đội giá cold-start. Vì thế cân nhắc monitor traffic tới các function có nhiều người dùng. Nếu thấy traffic lên cao, cân nhắc bật Provisioned Concurrency và tắt đi khi traffic xuống
- Các tác vụ truy cập các VPC (như truy xuất file từ EFS, gọi vào RDS) tốn kha khá CPU, cấp ít nhất 512M RAM.
Kiểm soát số lượng Lambda được chạy và tối ưu kết nối tới các tài nguyên khác#
Đối với mỗi tài khoản AWS, mỗi người dùng được phép chạy tối đa 500 lambda đang được warm trong cùng một thời điểm (con số này khác nhau ở các vùng khác nhau) Đây có thể là một con số lớn với một dịch vụ trung bình hoặc nhỏ hoặc một dịch vụ mang tính demo, nhưng với các dịch vụ lớn, có một vài điều cần phải lưu ý như sau:
- Mặc dù giới hạn 500 lambda đang được
warmrất lớn, nhưng với các dịch vụ nhiều người dùng, trong giờ cao điểm, việc cạn số lượng lambda có thể chạy vẫn có thể xảy ra - Các tài nguyên như RDS, ElastiCache có giới hạn số lượng connection cùng một lúc giới hạn, còn Lambda chạy độc lập vậy nên không có connection pool. Với mô tả vòng đời của Lambda như ở trên, các function kể cả khi không chạy vẫn sẽ giữ connection
Điều này gây ra chung một vấn đề: Gián đoạn dịch vụ. Dưới đây là mô tả hệ quả:
- Vượt quá số lượng lambda đang
warmtrong cùng một lúc sẽ khiến API chập chờn không ổn định. Ta không còn cách nào khác ngoài việc đợi để AWS kết thúc vòng đời của function - Mặc dù có thể tạm thời giải quyết giới hạn số lượng connection vào RDS bằng cách tăng cấu hình RDS Instance/Cluster, nhưng đây là một giải pháp tốn kém và không tối ưu do lượng connection vào RDS không phải lúc nào cũng luôn chạm ngưỡng và việc trả gấp 4 lần tiền để khắc phục vấn đề chỉ xảy ra trong 1/4 thời gian là một hành động ngu ngốc
Vậy, ta cần phải đưa ra giải pháp cho vấn đề này như sau:
- Phân cho các function Lambda quan trọng (như các API được gọi nhiều) một lượng invocation nhất định, điều này đảm bảo rằng function đó sẽ luôn có một lượng invocation và không bao giờ vượt quá lượng invocation đó, đảm bảo chúng luôn hoạt động và không gây flood các tài nguyên như RDS, ElastiCache. Xem hướng dẫn tại đây
- AWS cung cấp RDS Proxy để giải quyết vấn đề connection pool của Lambda vào RDS, sử dụng RDS Proxy (đặc biệt cho các function được invoke rất nhiều lần trong một thời gian ngắn) để đảm bảo RDS không bị flood bởi các function này
Như ở công ty hiện tại, tôi kết hợp cả hai phương án trên để tối ưu connection vào DB, và kết quả tương đối mĩ mãn:
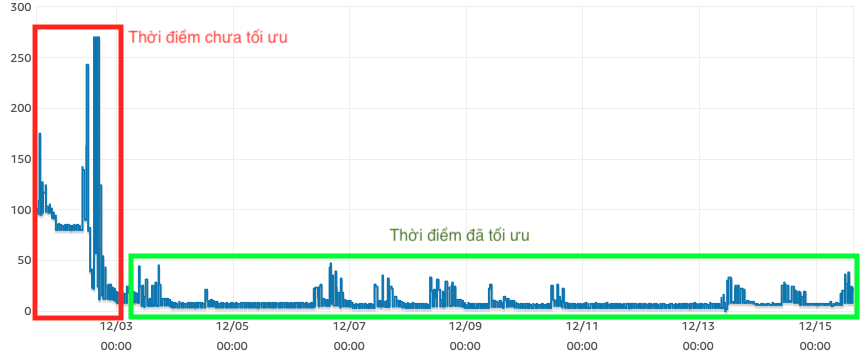
Database Connection Giảm Aperture
Thay vì số lượng connection luôn cao và có thể bị burst lên chạm ngưỡng connection limit, giờ mỗi khi burst lượng connection sẽ không quá cao như trước, đảm bảo hệ thống sẽ chạy ổn định hơn mà không phải trả quá nhiều tiền
Chú ý tạo endpoint cho các service#
Chắc hẳn bạn cũng để ý rằng, một khi Lambda đã nhập vào VPC (để dùng các tài nguyên chỉ nằm trong VPC), không thể truy cập các dịch vụ như S3, Secrets Manager được nữa do các dịch vụ này không nằm cùng dải mạng của VPC. Để khắc phục vấn đề này, ta cần cho phép VPC truy cập ra ngoài internet. Vô hình chung, việc đầu tiên của người thiết kế sẽ là config sao cho Lambda nằm trong dải mạng public và cho nó connect ra ngoài internet, vừa để phục vụ yêu cầu ra internet của function (nếu cần), vừa có thể access các dịch vụ của Lambda. ví dụ như topology dưới đây mô tả flow để truy cập các tài nguyên dịch vụ của AWS nếu bạn config để Lambda có thể connect ra ngoài internet:
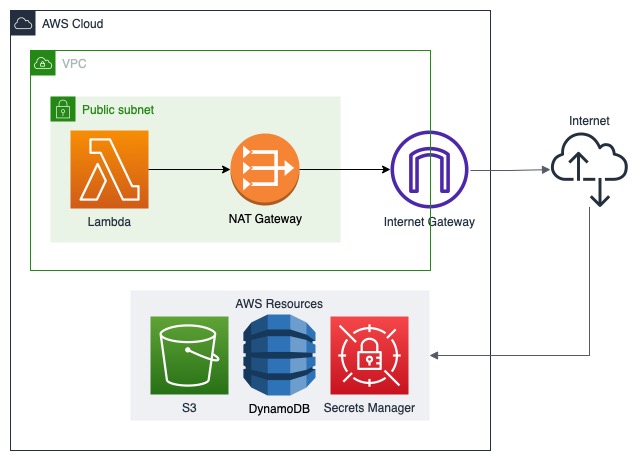
Ví dụ về network topology chưa tốt Aperture
Ta có thể thấy bất cập của mô hình này như sau:
- Truy cập tài nguyên yêu cầu Lambda phải gọi ra ngoài internet rồi sau đó gọi ngược lại vào mạng AWS, gây ra độ trễ khá cao
- Lambda phải được đặt trong dải mạng public để ra internet gây đội giá thành vận hành lên khá cao, do ta cần phải tạo NAT Gateway, Internet Gateway và trả tiền traffic ra ngoài internet
Để giải quyết vấn đề này, ta cần phải tạo các VPC endpoint để truy cập tài nguyên của AWS mà vẫn đảm bảo Lambda được đặt trong dải mạng private mà không bị đội giá thành và tốc độ nhanh hơn, như ở hình dưới đây:
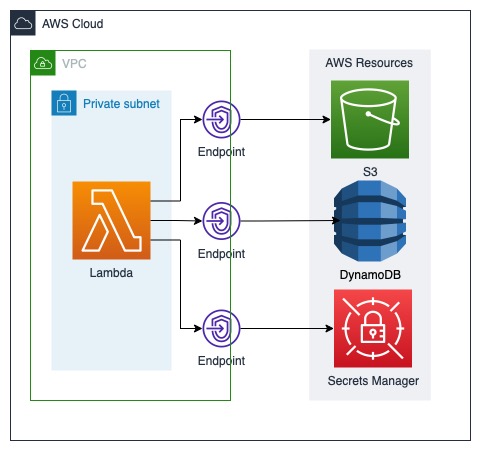
Ví dụ về network topology ổn Aperture
Để config endpoint, xem hướng dẫn này
Tổng kết#
Đây là các kinh nghiệm tôi rút ra được. Mong ai đó đọc được bài viết này sẽ thấy bài viết có hữu ích và tối ưu được lượng tiền sử dụng trên AWS
Nguồn tham khảo#
- AWS Lambda execution environment - AWS Lambda Document
- Memory and computing power - AWS Lambda Document
- Operating Lambda: Performance optimization – Part 1 - AWS Compute Blog
- Operating Lambda: Performance optimization – Part 2 - AWS Compute Blog
- Can Lambda and RDS Play Nicely Together? - Thundra Blog
- Reduce Cost and Increase Security with Amazon VPC Endpoints - AWS Architecture Blog
comments powered by Disqus