Phương pháp ma quỷ để gộp chung Pandas, NumPy và SciPy vào chung một layer lambda để chạy trên Python 3.10 mà không quá dung lượng 250M
Mở đầu câu chuyện#
Mọi thứ bắt đầu khi tôi được giao một task yêu cầu phải migrate tất cả function lambda của hệ thống từ Python 3.8 lên một phiên bản mới hơn do Python 3.8 sẽ kết thúc vòng đời (EOL) vào 10/2024. Sau một hồi cân nhắc thì tôi quyết định update lên 3.10. Mọi người có thể hỏi vì sao không update thằng lên 3.11+, câu trả lời đơn giản là vì nhiều thư viện Python hiện tại chưa support các bản mới như vậy, điển hình là PyTorch. Hơn nữa, các phiên bản mới có nhiều tính năng mới không dùng và có thể gây ra bug tiềm tàng. Dùng bản cũ ít tính năng thì sẽ bớt entropy để gây ra lỗi.
Công việc này bao gồm 3 phần:
- Kiểm tra các breaking change về library và syntax từ 3.8 sang 3.10 có thay đổi gì không (tức phải xem thay đổi của cả 3.9 và 3.10)
- Update các layer library có sẵn từ Python 3.8 lên 3.10
- Update các function và để bên tester làm việc
Việc review các breaking change xảy ra khá suôn sẻ, vì phần lớn các update từ 3.8 đến 3.10 chủ yếu là thêm tính năng chứ không có thay đổi lớn gì về cú pháp. Các thư viện có cải tiến mà tôi hay dùng là concurrent.futures cũng không có breaking change nào cả. Việc update phần lớn các layer library cũng đơn giản, ngay cả thư viện hay gặp vấn đề nhất là cffi cũng chạy luôn một cách thần kì, nhờ vậy phần lớn các layer đều migrate lên Python 3.10 khá nhanh chóng và chạy không có vấn đề gì. Tôi đã nghĩ mọi thứ như vậy là ổn, cho đến khi gặp phải vấn đề nan giải: Cho NumPy, SciPy và Pandas chạy được cùng với nhau.
Vấn đề kích thước với NumPy, SciPy và Pandas#
Nghiệp vụ mà tôi gặp phải yêu cầu phải có cả 3 thư viện SciPy, NumPy và Pandas chạy cùng với nhau. Nếu bạn dùng SciPy, NumPy và Pandas thì cũng hiểu các kích thước các thư viện này rất nặng. Ngoài code ra, các thư viện trên còn chứa cả thư viện phụ trợ kèm theo, các thư viện .so đã build ra (OpenBLAS và GFortran cho NumPy và SciPy, mỗi thư viện dùng một phiên bản) nên tổng cả thư mục này có kích thước lên tới 278M, trong khi AWS Lambda chỉ cho phép tổng TẤT CẢ các layer lại trong một function là 250M, tức là tôi đã quá 28M so với giới hạn, đấy là chưa kể phải chừa chỗ cho các layer và code khác.
Ở runtime Python 3.8, AWS cung cấp sẵn 2 layer sau:
AWSLambda-Python38-SciPy1x: Bao gồm SciPy và NumPyAWSSDKPandas-Python38: Bao gồm Pandas và NumPy
Và việc nhét một lúc cả 2 layer này vào một function cũng gây ra lỗi quá kích thước nốt. Tôi đã exploit việc Pandas không có thư viện rời, nên đã tải xuống một layer chỉ có một mình Pandas mà không có NumPy:
pip install pandas --target python
rm -r python/numpy*/
Vậy là layer mới này chỉ chứa mỗi Pandas và các dependency khác của nó nên nhỏ hơn, chỉ còn khoảng 70M. Khi dùng thì chọn cả layer này vào cùng với AWSLambda-Python38-SciPy1x, thì cả kết quả ta được 1 function có đầy đủ Pandas, SciPy và NumPy cùng một chỗ. Như ở trên theo lý thuyết thì không thể, nhưng có lẽ bản build custom của AWS đã tối ưu việc dynamic linking tới các thư viện có sẵn trong môi trường nên đã tiết kiệm được thêm vài chục MB.
Nhưng khi lên runtime Python 3.10, AWS chỉ cung cấp một layer AWSSDKPandas-Python310 chứa Pandas và NumPy mà không cung cấp layer nào chứa SciPy như 3.8 cả. Vậy là tôi đứng giữa ngã ba đường, tạo layer chứa cả 3 thì nặng nhét không vừa, mà tạo layer chứa mỗi Pandas để dùng với layer SciPy có sẵn như hồi dùng Python 3.8 thì vô nghĩa vì làm gì có layer nào như AWSLambda-Python38-SciPy1x mà dùng. Trong bài toán của tôi, thì ngoài 3 thư viện trên thì cần phải trống khoảng 15-20M nữa để dành cho các layer khác. Phúc bất trung lai hoạ vô đơn chí, tôi vừa phải nhét 3 cái thư viện to đùng vào 1 layer mà vừa phải đảm bảo tạo ra cái layer có kích thước nhỏ hơn 230M.
Để giải quyết vấn đề này, tôi đưa ra 5 phương án:
| Phương án | Vấn đề gặp phải | |
|---|---|---|
| 1 | Giữ nguyên các function cần 3 thư viện trên ở Python 3.8 | Yêu cầu bắt buộc phải nâng cấp lên 3.10 do vấn đề security, chỉ giữ lại layer và runtime 3.8 để phục vụ nhu cầu code legacy của khách hàng |
| 2 | Nhét tất cả code và thư viện vào Docker do AWS Lambda có thể chạy 1 Docker image lên tới 10G | Cold start của Lambda Docker khá lớn cộng với cold start khi chạy code lần đầu, lên tới 8-12s hoặc hơn, nên chỉ phù hợp với các background task để tránh việc người dùng phải đợi cold start. Hiện tại chỉ có các trường hợp dùng các library lớn như Torch, Tensorflow là phải dùng đến Docker, trong khi rất nhiều function người dùng thường xuyên gọi vào phải dùng đến NumPy, SciPy và Pandas. Cold start lớn quá khiến người dùng bực bội vì đợi lâu (khách hàng đã thực sự than phiền vì điều này). Hơn nữa đưa code vào Docker sẽ khiến quá trình dev trở nên khó khăn hơn do phải build cả Docker Image lên để test. |
| 3 | Mount EFS vào function và cài thư viện vào đó, sau đó dùng một vài trick để Python có thể detect được vị trí thư viện và lôi ra sử dụng | EFS không chịu được tải cao, khi có quá nhiều client connect vào thì EFS sẽ quá tải. Việc access liên tục các file nhỏ trong EFS cũng không hiệu quả, đội giá chi phí (gồm chi phí lưu trữ và băng thôn). Hơn nữa thêm EFS vào là thêm một điểm chết vào hệ thống |
| 4 | Build lấy một bản NumPy, Pandas và SciPy riêng và optimize các thư viện OpenBLAS, GFortran cho họ | Việc build khá khó và tốn nhiều thời gian, không hề có hướng dẫn gì trên mạng. Chạy bản build custom dễ xảy ra lỗi bí hiểm rất khó sửa. |
| 5 | Xoá bớt code trong các thư viện đi cho nhỏ hơn 230M (MA QUỶ 💀💀💀) | Không rõ bên trong có những gì an toàn để xoá. Không nói cũng biết đây là bad practice. |
Sau khi thử cả 4 phương án, tôi thấy phương án 4 là nhanh nhất và chưa xảy ra vấn đề gì cả. Câu chuyện cụ thể sẽ được đề cập ở dưới.
Con đường dẫn tới phương án ma quỷ#
Sau khi vật lộn với việc build NumPy, Pandas và SciPy, đối phó với thư viện BLAS và GFortran của Amazon Linux, tôi vẫn không tìm được ra cách build kèm static link các thư viện đó mà không vượt quá kích thước 230M ở trên. Và chẳng có con AI nào đưa ra một phương án ra gì để giải thoát tôi khỏi vấn đề nan giải này.
Sau rất nhiều bao Sài Gòn bạc và đào xới các thể loại GitHub Issues và StackOverflow thì cuối cùng tôi tìm ra một ý tưởng clean up repo SciPy khá tà đạo trong một cái Issue của GitHub repo keithrozario/Klayers:
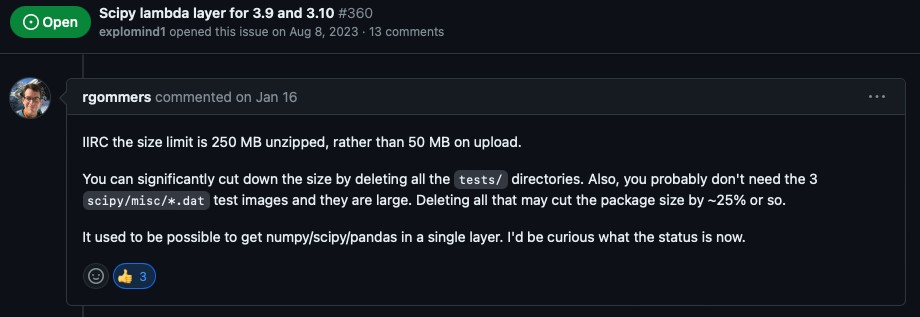
Ý tưởng clean up repo SciPy trên GitHub Issue keithrozario/Klayers
Như đề cập, thì tôi có thể xoá bay xoá biến thư mục tests trong các folder con và các file scipy/misc/*.dat trong SciPy mà không gây lỗi cho thư viện. Sau một hồi điều tra trong code của SciPy, thì có vẻ thư mục tests này chỉ được dùng trong lúc test khi build xong. Còn các file .dat là các file dataset mẫu của SciPy, ascent.dat là file chứa ảnh 8bit grayscale, ecg.dat để chứa dữ liệu điện tâm đồ mẫu, còn face.dat là chứa ảnh của gấu mèo 🦝. Thực tế là scipy.misc này đã bị deprecate từ bản SciPy v1.10.0, nhưng thế quái nào nó vẫn ở đây để làm nặng cái thư viện này.
Không chỉ dừng lại ở SciPy, tôi thấy NumPy cũng có các directory tests như vậy, kích thước cũng khủng không kém. Nên tôi cũng xoá sạch các directory test đó đi luôn. Có vẻ do dùng chung mesos làm build backend nên chúng có chung một kết quả như vậy.
Cuối cùng, để tiết kiệm hết mức, tôi xoá hết các directory dist-info đi và cũng không tạo bytecode sau khi build để tiết kiệm dung lượng hơn nữa.
Kết quả, tôi thu được một layer có kích thước vỏn vẹn chỉ còn 192M, tức là tới tiết kiệm được tới 80M không dùng đến. Vậy là tôi đã vượt chỉ tiêu tận hơn 30M.
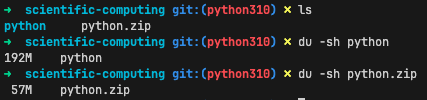
Kết quả sau khi cleanupblog.haivq.com
Phương pháp tạo ra layer ma quỷ#
Lưu ý: Viêc can thiệp trực tiếp vào source code của thư viện là một việc rất tệ, dễ gây ra lỗi khi không tìm hiểu kĩ, mà kể cả tìm hiểu kĩ vẫn có thể gây lỗi như thường. Nếu có thể bạn hãy dùng cách khác thay vì phương pháp ma quỷ này 💀💀💀.
Vậy các bước để tạo ra một layer nhỏ có thể tóm gọn trong các bước sau đây:
# tải thư viện về, không tạo bytecode và chỉ tải bản CPython
pip install numpy pandas scipy --no-compile --implementation cp -t python
# Xoá hết các thư mục dist-info không cần đến
rm -r *.dist-info
# Xoá hết các thư mục lá (leaf directory) tests của tất cả các thư viện
find . | grep -E "*/tests$" | xargs rm -rf
# Xoá hết bytecode mà Python sinh ra nếu có
find . | grep -E "(/__pycache__$|\.pyc$|\.pyo$)" | xargs rm -rf
# Xoá cả pyproject vì không cần đến
find . | grep -E "pyproject.toml$" | xargs rm -rf
# Xoá các file .dat trong SciPy không dùng tới
find . | grep -E "scipy\misc\*.dat$" | xargs rm -rf
Như vậy là tôi đã hoàn thành việc giảm kích thước layer. Và sau khi test trên lambda thì nó THỰC SỰ ĐÃ CHẠY 💀💀💀. Có lẽ đây là phương pháp ma quỷ nhất mà tôi từng biết để nhồi nhét thư viện vào trong một layer Lambda.
Lý do lịch sử về việc xuất hiện thư mục tests trong thư viện SciPy/NumPy#
Để giải thích cho lý do vì sao thư mục tests lại được nhét vào trong thư viện SciPy/NumPy, anh bạn Hà Lan rgommers, cũng là người maintain NumPy và SciPy, đã đưa ra giải thích như sau:
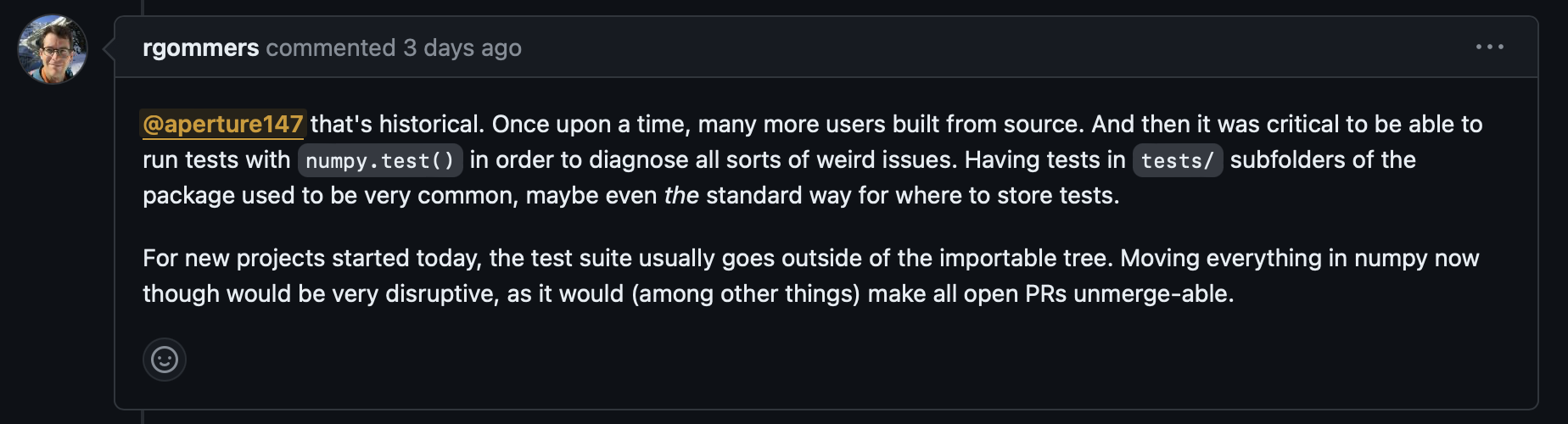
Lý do thư mục tests được đưa vào trong thư viện
keithrozario/Klayers
Tóm tắt ngắn gọn lại, là ngày xưa nhiều người build NumPy/SciPy lại từ đầu, khi build xong họ phải chạy numpy.test() để kiểm tra xem có lỗi lầm khù khoằm gì xảy ra hay không. Giờ không cần thiết phải build lại NumPy và SciPy nữa, nhưng bây giờ can thiệp bất kì điều gì trong NumPy và SciPy đều rất nguy hiểm, dễ có lỗi xảy ra (vì giờ cái project to quá rồi). Cái gì không hỏng thì tốt nhất không nên động vào nên thôi đành kệ thư mục tests đó vậy.
Tổng kết#
Như vậy là thông qua việc inspect thư viện Python đã install, tôi đã tiết kiệm rất nhiều dung lượng khi đưa chúng vào layer. Điều này làm tôi nhớ tới câu chuyện của NaughtyDog khi làm Crash Bandicoot, khi Andy Gavin đã tìm cách xoá bớt thư viện C của Sony đi để giải phóng RAM trên máy PS1 để họ có thể load được nhiều nội dung hơn trong game.
Nguồn tham khảo#
comments powered by Disqus